
I hope to provide more packages and more informations to this list from times to times. If you have some specific questions regarding a package or have some recommendations, feel free to leave a comment, I will have a look!
Machine learning means so many possible tasks, comes with so many packages and tools that it is hard to have an idea of which one to use. I am just listing the one I find really useful. They are not better than the packages I do not use and I cannot guarantee they are absolutely bug free, but they are robust enough to work with!
Linux tools
A good terminal will be your best friend.
i="1"
for filename in ./pdfs/*.pdf; do
i="$((i+1))"
if [ "$i" -gt 20 ]; then
break
fi
echo "Processing $filename file..."
pdf2txt.py -m 2 "$filename" >> "txts/$(basename "$filename" .pdf).txt"
done
tabview
Probably the best tool to navigate through a CSV file, in the terminal. It is really light, fast, supports many VIM commands. Here is the repo.
csvkit
Install it from pip. It comes with a lot of handy tools:
-
csvstat -
csvlookthough I prefer tabview,csvlook my_data.csv > my_data.mdallows to display a csv file in markdown.
Combined with head you can navigate through various files really fast. There actually is whole website dedicated to this.
glances
This allows you to see how busy your machine is when running an algorithm.
PDF to text files
pdf2txt.py
Useful to extract text from pdf files. There is no perfect solution (as far as I know) for this task, but this one is a good starting point.
Tesseract (and ImageMagick)
Another approach to extracting text from pdf files is using OCR (Optical Character Recognition). Tesseract does a great job but importing pdf directly can lead to errors. However, ImageMagick does a great job at turning pdfs to pngs.
echo "Processing $filename file..."
convert -density 300 "$filename[0-1]" -quality 90 "output.png"
tesseract -l fra "output-0.png" "output-0"
tesseract -l fra "output-1.png" "output-1"
cat "output-0.txt" "output-1.txt" > "ocr$(basename "$filename" .pdf).txt"
rm "output-0.txt" "output-1.txt" "output-0.png" "output-1.png"
R
When installing R, and it happened to me many times, I love running the following script. It feels like coming home. I will not go through all the details of each package, it is just that it will be useful for me to have this code around :)
load.lib<-function(libT,l=NULL)
{
lib.loc <- l
print(lib.loc)
if (length(which(installed.packages(lib.loc=lib.loc)[,1]==libT))==0)
{
install.packages(libT, lib=lib.loc,repos='http://cran.us.r-project.org')
}
}
data_reading_libraries <- c(
"readr",
"readstata13"
)
machine_learning_libraries <- c(
"xgboost",
"glmnet",
"randomForest",
"Rtsne",
"e1071"
)
data_libraries <- c(
"data.table",
"FeatureHashing",
"dplyr",
"Matrix"
)
string_libraries <- c(
"stringdist",
"tm"
)
plot_libraries <- c(
"ggplot2",
"RColorBrewer",
"fields",
"akima"
)
favorite_libs <- c(data_reading_libraries,
machine_learning_libraries,
data_libraries,
string_libraries,
plot_libraries)
for(lib in favorite_libs){load.lib(lib)}
General stuff
Reading data
readr
If you have been using the default csv reader in R read.csv, you must be familiar with its drawbacks : slow, many parameters, a parser which sometimes fails… readr on the other hand is super fast, robust and comes with read_csv and read_csv2 depending on the csv standard your file relies on. (The good thing with standard being that there always are many versions of them…)
XML
It allows to read XML files (obviously) but also HTML tables (yes, some people actually use this to transfer data, though it makes the whole file much bigger because of so many HTML tags…)
Machine learning libraries
glmnet
A library that enables to perform elastic net regressions. Has a cross validation method which enjoys nice properties of the path of optimization, which allows to evaluate a path of solutions as fast as a single model.
randomForest
The standard if you want to use random forests with R. Link to the cran page
e1071
I tried its “competitor” (kernlab), but prefered this one.
Rtsne
Wrapper for the C++ implementation of Barnes-Hut t-Distributed Stochastic Neighbor Embedding. Was the fastest tSNE implementation when I tried them.
Data viz
coefplot
Visualizing linear regressions is now simple.
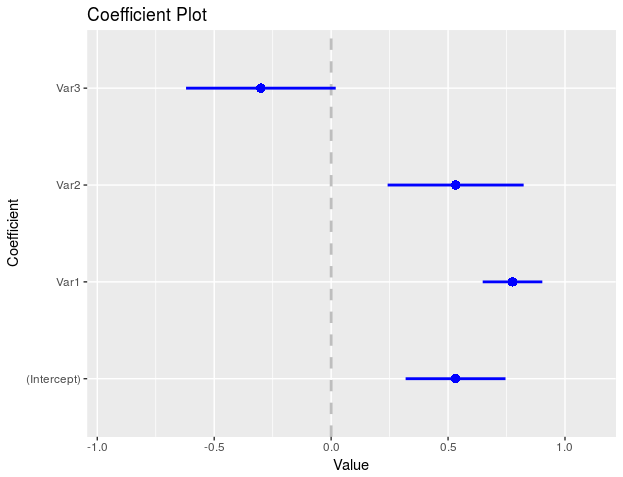
require(coefplot)
N <- 10
P <- 3
X <- matrix(rnorm(n = N*P), nrow = N)
w <- rnorm(P)
Y <- X %*% w + rnorm(P)
my_data <- cbind.data.frame(Y,X)
colnames(my_data) <- c("Y",paste0("Var",1:3))
model <- lm(Y ~ ., data = my_data)
coefplot(model)
corplot
A matrix of correlation can be quite ugly. This one just makes it easier to read, with colors…
forestFloor
Wouldn’t it be great to have something that tells you a little bit more about your random forests models ? This package can.
Python
General stuff
tqdm
tqdm is one of the most useful package I discovered. Though it actually does not perform any operation or handles your dataframes smartly, it shows a progress bar for the loops you want it to. Still not convinced ? With it, you can keep track on every feature engineering job you launch, see which ones are never going to end without the pain of writing all these bars yourself.
pandas
The industry standard for dataframes.
numpy
The industry standard for numeric operations
csv
Easy manipulation of csv files. The method DictReader is particularly useful when one needs to stream from a csv file.
unicodecsv
import unicodecsv as csv
Solves so many issues.
Machine learning libraries
sk-learn
A collection of robust and well optimized methods. A must have.
xgboost, catboost, gbm light
Libraries dedicated to gradient boosting. Amazing performances, amazingly robust.